PromtTuning улучшаем LLM без переобучения
MLPops / November 20, 2024
10 мин.
В быстро развивающейся области больших языковых моделей (LLM) критически важно оставаться на вершине современных подходов, таких как быстрая настройка. Эта техника, применяемая к уже обученным базовым моделям , повышает производительность без высоких вычислительных затрат, связанных с традиционным обучением моделей.
PromtTuning - это метод, разработанный для повышения производительности предварительно обученной языковой модели без изменения ее весов. Вместо обучения и изменения весов моделей, PromtTuning корректирует подсказки, которые направляют реакцию модели.
Если смотрим на похожие методы, то это LoRA обучение, но опять же LoRA представляет собой более эффективный метод адаптации предобученных языковых моделей (LLM) по сравнению с обычным обучением. Обычное обучение LLM включает в себя полное обновление всех параметров модели на большом наборе данных, что требует значительных вычислительных ресурсов и времени. В отличие от этого, PromtTuning использует специализированные подсказки (prompt) для направления модели на выполнение конкретных задач, не изменяя ее параметры, что позволяет экономить ресурсы. LoRA, в свою очередь, добавляет небольшие матрицы (низкого ранга) к весам модели, позволяя адаптировать ее поведение без необходимости полного переобучения, что также делает процесс более эффективным
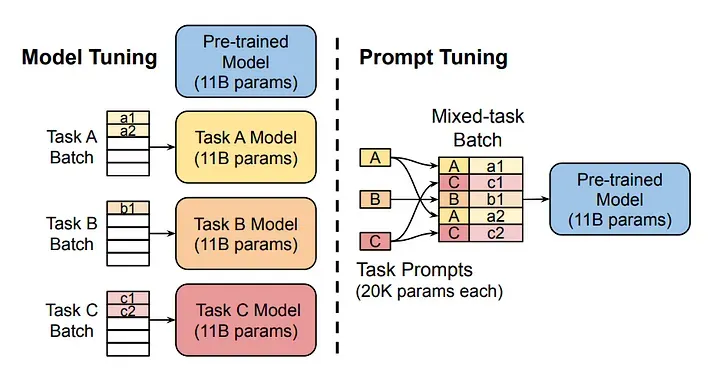
Мы создаем по сути суперпромпт, позволяя модели улучшать часть промпта с помощью своих накопленных знаний. Однако эта конкретная часть промпта не может быть переведена на естественный язык. Это как если бы мы освоили выражение своих мыслей в эмбеддингах и генерацию высокоэффективных промптов.
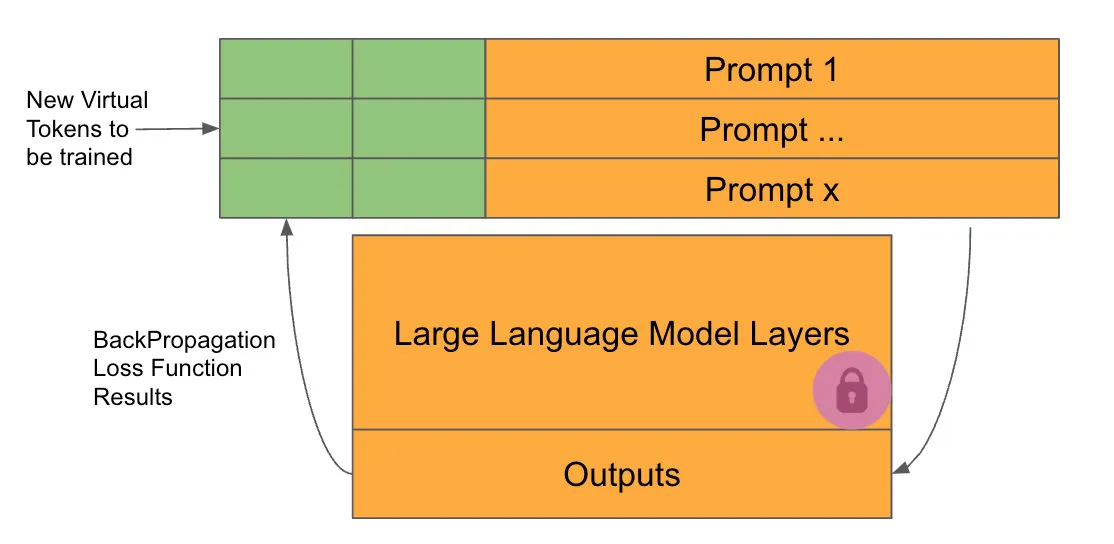
В каждом цикле обучения единственные веса, которые могут быть изменены для минимизации функции потерь, — это те, которые интегрированы в промпт.
Основное следствие этой техники заключается в том, что количество параметров для обучения действительно невелико. Однако мы сталкиваемся со вторым, возможно, более значительным следствием, а именно с тем, что, поскольку мы не изменяем веса предобученной модели, модель не меняет свое поведение поведение и не стирает никакую информацию, которую она ранее усвоила.
Обучение проходит быстрее и экономичнее. Более того, мы можем обучать различные модели, и во время инференса нам нужно загрузить только одну базовую модель вместе с новыми меньшими обученными моделями, поскольку веса оригинальной модели не были изменены.
Prompt engineering
Второе на что похоже PromtTuning - это Prompt engineering
Prompt engineering, не включает в себя обучение или переобучение. Он полностью основан на том, что пользователь разрабатывает промпты для модели. Это требует тонкого понимания возможностей обработки модели и использует встроенные в модель знания. Prompt engineering не требует никаких вычислительных ресурсов, поскольку он основывается исключительно на стратегической формулировке входных данных для достижения результатов.
Сравнение
Каждая из этих техник предлагает различный подход к использованию возможностей предобученных моделей. Выбор между ними зависит от конкретных потребностей приложения, таких как доступность вычислительных ресурсов, необходимость в кастомизации модели и желаемый уровень взаимодействия с параметрами обучения модели.
| Метод | Объем ресурсов | Требуется обучение | Подходит для |
|---|---|---|---|
| Fine-Tuning | Высокий | Да | Задачи, требующие глубокой настройки модели |
| Prompt Tuning | Низкий | Да | Поддержание целостности модели при выполнении задач |
| Prompt Engineering | Не трубуются | Нет | Быстрая адаптация без вычислительных затрат |
Пример PromtTuning
Эта библиотека содержит реализацию различных техник Fine-Tuning от Hugging Face, включая Prompt Tuning.
!pip install -q peft==0.8.2
!pip install -q datasets==2.14.5Из библиотеки transformers мы импортируем необходимые классы для создания экземпляра модели и токенизатора.
from transformers import AutoModelForCausalLM, AutoTokenizerЗагрузка модели и токенизатора.
Bloom — одна из самых маленьких и самых умных моделей, доступных для обучения с помощью библиотеки PEFT с использованием Prompt Tuning. Я выбираю самый маленький, чтобы сократить время обучения и избежать проблем с памятью.
model_name = "bigscience/bloomz-560m"
# model_name="bigscience/bloom-1b1"
NUM_VIRTUAL_TOKENS = 4
NUM_EPOCHS = 6
tokenizer = AutoTokenizer.from_pretrained(model_name)
foundational_model = AutoModelForCausalLM.from_pretrained(model_name, trust_remote_code=True)Инференс с предобученной моделью bloom
Если вы хотите получить более разнообразные и оригинальные генерации, раскомментируйте параметры: temperature, top_p и do_sample в model.generate ниже.
При использовании конфигурации по умолчанию ответы модели остаются последовательными при каждом вызове.
# Эта функция возвращает выходные данные, полученные от модели, и входные данные.
def get_outputs(model, inputs, max_new_tokens=100):
# Генерируем выходные данные с помощью модели, используя заданные входные данные и параметры.
outputs = model.generate(
input_ids=inputs["input_ids"], # Используем идентификаторы входных данных (токены) для генерации.
attention_mask=inputs["attention_mask"], # Используем маску внимания, чтобы указать, какие токены следует учитывать.
max_new_tokens=max_new_tokens, # Устанавливаем максимальное количество новых токенов для генерации.
# temperature=0.2, # Параметр температуры для контроля случайности генерации.
# top_p=0.95, # Параметр top-p (nucleus sampling) для контроля разнообразия генерации.
# do_sample=True, # Указывает, следует ли использовать случайную выборку при генерации.
repetition_penalty=1.5, # Устанавливаем штраф за повторение, чтобы избежать избыточности в выходных данных.
early_stopping=True, # Разрешаем модели остановиться до достижения максимальной длины, если это возможно.
eos_token_id=tokenizer.eos_token_id, # Указываем идентификатор токена конца последовательности для завершения генерации.
)
return outputs # Возвращаем сгенерированные выходные данные.Поскольку мы хотим иметь две разные обученные модели, я создам два отдельных промта.
Первая модель будет обучена на датасете, содержащем промты, а вторая — на датасете мотивационных предложений.
Первая модель получит промт “I want you to act as a motivational coach.”, а вторая модель получит “There are two nice things that should matter to you:“
Но сначала я собираюсь собрать некоторые результаты от модели без Fine-Tuning.
input_prompt = tokenizer("I want you to act as a motivational coach. ", return_tensors="pt")
foundational_outputs_prompt = get_outputs(foundational_model, input_prompt, max_new_tokens=50)
print(tokenizer.batch_decode(foundational_outputs_prompt, skip_special_tokens=True))["I want you to act as a motivational coach. Don't be afraid of being challenged."]input_sentences = tokenizer("There are two nice things that should matter to you:", return_tensors="pt")
foundational_outputs_sentence = get_outputs(foundational_model, input_sentences, max_new_tokens=50)
print(tokenizer.batch_decode(foundational_outputs_sentence, skip_special_tokens=True))['There are two nice things that should matter to you: the price and quality of your product.']Оба ответа более или менее корректны. Любая из моделей Bloom является предобученной и может генерировать предложения точно и осмысленно. Давайте посмотрим, будут ли ответы после обучения равны или сгенерированы более точно.
Tuning
Мы можем использовать одну и ту же конфигурацию для обучения обеих моделей.
from peft import get_peft_model, PromptTuningConfig, TaskType, PromptTuningInit
generation_config = PromptTuningConfig(
task_type=TaskType.CAUSAL_LM, # This type indicates the model will generate text.
prompt_tuning_init=PromptTuningInit.RANDOM, # The added virtual tokens are initializad with random numbers
num_virtual_tokens=NUM_VIRTUAL_TOKENS, # Number of virtual tokens to be added and trained.
tokenizer_name_or_path=model_name, # The pre-trained model.
)Создание двух моделей Prompt Tuning.
Мы создадим две идентичные модели prompt tuning, используя одну и ту же предобученную модель и одну и ту же конфигурацию.
peft_model_prompt = get_peft_model(foundational_model, generation_config)
print(peft_model_prompt.print_trainable_parameters())trainable params: 4,096 || all params: 559,218,688 || trainable%: 0.0007324504863471229peft_model_sentences = get_peft_model(foundational_model, generation_config)
print(peft_model_sentences.print_trainable_parameters())trainable params: 4,096 || all params: 559,218,688 || trainable%: 0.0007324504863471229Как видишь, мы будем обучать 0.001% доступных параметров.
Теперь мы создадим аргументы обучения и будем использовать одну и ту же конфигурацию в обоих обучениях.
from transformers import TrainingArguments # Импортируем класс TrainingArguments из библиотеки transformers.
def create_training_arguments(path, learning_rate=0.0035, epochs=6):
# Создаем объект TrainingArguments с заданными параметрами обучения.
training_args = TrainingArguments(
output_dir=path, # Указываем директорию, куда будут записаны предсказания модели и контрольные точки.
use_cpu=True, # Указываем, что необходимо использовать CPU (это важно для кластеров на CPU).
auto_find_batch_size=True, # Включаем автоматический поиск подходящего размера пакета, который поместится в память.
learning_rate=learning_rate, # Устанавливаем скорость обучения (выше, чем при полном Fine-Tuning).
num_train_epochs=epochs, # Устанавливаем количество эпох для обучения.
)
return training_args # Возвращаем созданные аргументы обучения.import os # Импортируем модуль os для работы с файловой системой.
working_dir = "./" # Устанавливаем рабочую директорию как текущую.
# Лучше всего хранить модели в отдельных папках.
# Создаем имена директорий для хранения моделей.
output_directory_prompt = os.path.join(working_dir, "peft_outputs_prompt") # Создаем путь к директории для хранения выходных данных по запросам.
output_directory_sentences = os.path.join(working_dir, "peft_outputs_sentences") # Создаем путь к директории для хранения выходных данных по предложениям.
# Создаем директории, если они не существуют.
if not os.path.exists(working_dir): # Проверяем, существует ли рабочая директория.
os.mkdir(working_dir) # Если не существует, создаем рабочую директорию.
if not os.path.exists(output_directory_prompt): # Проверяем, существует ли директория для выходных данных по запросам.
os.mkdir(output_directory_prompt) # Если не существует, создаем директорию для выходных данных по запросам.
if not os.path.exists(output_directory_sentences): # Проверяем, существует ли директория для выходных данных по предложениям.
os.mkdir(output_directory_sentences) # Если не существует, создаем директорию для выходных данных по предложениям.Нам нужно указать директорию, содержащую модель, при создании TrainingArguments.
training_args_prompt = create_training_arguments(output_directory_prompt, 0.003, NUM_EPOCHS)
training_args_sentences = create_training_arguments(output_directory_sentences, 0.003, NUM_EPOCHS)Обучение
Мы создадим объект тренера (trainer), по одному для каждой модели, которую нужно обучить.
from transformers import Trainer, DataCollatorForLanguageModeling # Импортируем класс Trainer и DataCollatorForLanguageModeling из библиотеки transformers.
def create_trainer(model, training_args, train_dataset):
# Создаем объект Trainer для обучения модели с заданными параметрами.
trainer = Trainer(
model=model, # Передаем PEFT-версию основной модели (например, bloomz-560M).
args=training_args, # Передаем аргументы для обучения, определенные ранее.
train_dataset=train_dataset, # Указываем набор данных, который будет использоваться для обучения модели.
data_collator=DataCollatorForLanguageModeling(
tokenizer, mlm=False # Создаем коллатор данных для языкового моделирования; mlm=False указывает, что не следует использовать маскированное языковое моделирование.
),
)
return trainer # Возвращаем созданный объект Trainer.# Обучаем первую модель
trainer_prompt = create_trainer(peft_model_prompt, training_args_prompt, train_sample_prompt)
trainer_prompt.train()# Обучаем вторую модель
trainer_sentences = create_trainer(peft_model_sentences, training_args_sentences, train_sample_sentences)
trainer_sentences.train()Менее чем за 10 минут (время CPU на M1 Pro) мы обучили 2 разные модели с двумя разными задачами, используя одну и ту же базовую модель.
Сохраняем модель
Мы собираемся сохранить модели. Эти модели готовы к использованию, при условии, что у нас в памяти есть предобученная модель, на основе которой они были созданы.
trainer_prompt.model.save_pretrained(output_directory_prompt)
trainer_sentences.model.save_pretrained(output_directory_sentences)Инференс
Вы можете загрузить модель из ранее сохраненного пути и попросить модель сгенерировать текст на основе нашего предыдущего ввода.
from peft import PeftModel # Импортируем класс PeftModel из библиотеки peft.
# Загружаем модель PEFT (Parameter-Efficient Fine-Tuning) из предварительно обученной модели.
loaded_model_prompt = PeftModel.from_pretrained(
foundational_model, # Указываем основную модель, из которой будет загружена PEFT-модель.
output_directory_prompt, # Указываем директорию, из которой будут загружены веса модели.
# device_map='auto', # Опция для автоматического распределения модели по доступным устройствам (например, GPU).
is_trainable=False, # Указываем, что модель не подлежит дообучению (не обучаемая).
)loaded_model_prompt_outputs = get_outputs(loaded_model_prompt, input_prompt)
print(tokenizer.batch_decode(loaded_model_prompt_outputs, skip_special_tokens=True))['I want you to act as a motivational coach. You will be helping students learn how they can improve their performance in the classroom and at school.']Если мы сравним оба ответа, что-то изменилось.
- Pretrained Model - I want you to act as a motivational coach. Don’t be afraid of being challenged.
- Fine-Tuned Model - I want you to act as a motivational coach. You can use this method if you’re feeling anxious about your.
Мы должны помнить, что мы обучали модель всего несколько минут, но этого было достаточно, чтобы получить ответ, ближе к тому, что мы искали.
loaded_model_prompt.load_adapter(output_directory_sentences, adapter_name="quotes")
loaded_model_prompt.set_adapter("quotes")loaded_model_sentences_outputs = get_outputs(loaded_model_prompt, input_sentences)
print(tokenizer.batch_decode(loaded_model_sentences_outputs, skip_special_tokens=True))['There are two nice things that should matter to you: the weather and your health.']Со второй моделью мы получили похожий результат.
- Pretrained Model - There are two nice things that should matter to you: the price and quality of your product
- Fine-Tuned Model - There are two nice things that should matter to you: the weather and your health.
Заключение
Prompt Tuning — это удивительная техника, которая может сэкономить нам часы обучения и значительную сумму денег. В ноутбуке мы обучили две модели всего за несколько минут, и мы можем иметь обе модели в памяти, предоставляя услуги разным клиентам.
Вы можете изменить количество эпох для обучения, количество виртуальных токенов и модель в третьей ячейке. Однако есть много конфигураций для изменения.