Векторные базы данных
MLPops / December 02, 2024
8 мин.
Введение
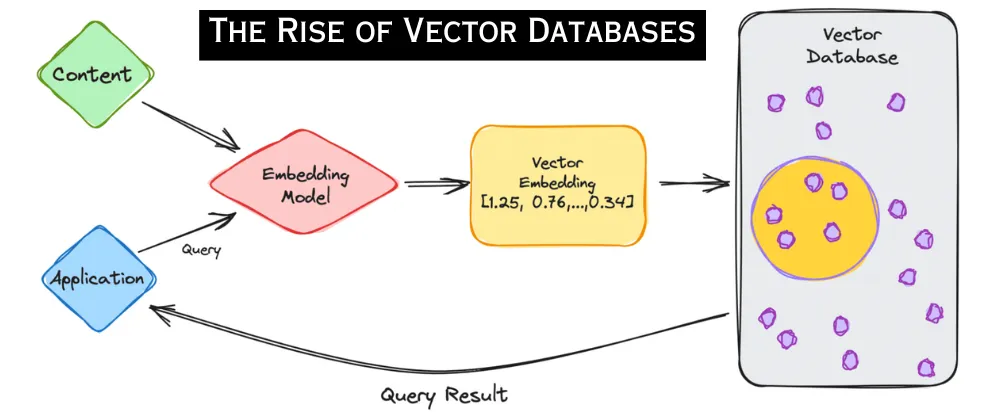
Векторные базы данных — это специализированные системы хранения данных, разработанные для сохранения, управления и эффективного запроса векторов высокой размерности. Такие векторы часто представляют собой сложные данные, такие как текстовые представления (эмбеддинги), изображения, аудиофайлы или другие особенности, полученные из машинного обучения.
Ключевые функции
- Хранение векторов: Оптимизированное хранение для векторов высокой размерности.
- Поиск по схожести: Быстрые и эффективные поиски ближайших соседей.
- Масштабируемость: Возможность работы с миллионами или миллиардами векторов.
- CRUD-операции: Поддержка операций создания, чтения, обновления и удаления векторов.
- Фильтрование метаданных: Сочетание поиска векторов с запросами на основе метаданных.
Популярные решения
Pinecone
- Облачная векторная база данных
- Ключевые функции:
- Обновление векторов в реальном времени
- Гибридный поиск
- Безопасность и надёжность для Enterprise решений
Weaviate
- Открытый поисковый движок на векторах
- Уникальные особенности:
- Интерфейс запросов на основе GraphQL
- Поддержка мультиарендности
- Встроенные модули векторизации
Milvus
- Распределённая векторная база данных
- Преимущества:
- Высокая производительность на больших наборах данных
- Гибкие опции для развёртывания
- Активное сообщество открытого исходного кода
Qdrant
- Движок векторного поиска по схожести
- Особенности:
- Фильтрование на основе полей данных
- Соответствие ACID
- Пользовательские функции оценки
ChromaDB
- Лёгкая встроенная векторная база данных
- Лучше подходит для:
- Локальной разработки
- Небольших и средних проектов
- Быстрого прототипирования
Типичные сценарии использования
Семантический поиск
- Понимание естественного языка: Преобразование поисковых запросов в векторные представления, чтобы найти значение намерения, а не просто ключевые слова.
- Сходство документов: Поиск похожих документов на основе содержащихся в них значений.
- Рекомендации контента: Генерация личных предложений контента, ориентированного на пользователя.
Поиск изображений
- Визуальное сходство: Поиск визуально похожих изображений, поддержка обратного поиска по изображениям, а также возможность сопоставления изображений по стилю.
- Поиск продуктов: Использование визуального поиска для поиска товаров в электронной коммерции, реализация функции “покупка по образу”, а также нахождение похожих товаров в различных категориях.
- Приложения компьютерного зрения: Распознавание и сопоставление лиц, обнаружение и классификация объектов, а также понимание сцен и их извлечение.
Рекомендательные системы
- Рекомендации продуктов: Генерация предложений типа “покупатели также приобрели”, персонализированный поиск товаров и поддержка возможностей перекрёстных продаж.
- Персонализация контента: Персонализация новостных лент, предложения релевантных статей или медиа, создание рекомендаций, основанных на предпочтениях пользователя.
- Коллаборативная фильтрация: Поиск схожих профилей пользователей, генерация рекомендаций на основе поведения и поддержка связей в социальных сетях.
Обнаружение аномалий
- Предотвращение мошенничества: Обнаружение необычных паттернов транзакций, выявление подозрительного поведения и флагирование потенциальных угроз безопасности.
- Мониторинг системы: Обнаружение аномалий в системе, мониторинг производительности и выявление потенциальных отказов.
- Обеспечение качества: Обнаружение дефектов в производстве, мониторинг качества продукции и выявление отклонений в процессе.
Архитектурные аспекты
Слой хранения
- Управление векторными данными: Эффективные форматы хранения для данных высокой размерности, использование методов сжатия данных (таких как Product Quantization или Scalar Quantization), компромиссы между хранением в памяти и на диске в зависимости от шаблонов доступа и требований по задержке.
- Хранение метаданных: Структурированное хранение данных, связанных с векторами, с гибкой поддержкой схемы; эффективная связь между векторами и метаданными через оптимизированные индексы.
- Поддержка разных форматов векторов: Поддержка различных форматов и типов размерности векторов для обеспечения гибкости в обработке.
Индексные структуры
- Поддержка множества типов индексов: Поддержка различных типов индексов (HNSW, IVF, LSH) для различных сценариев использования.
- Обновление и обслуживание индексов: Минимальное время простоя при обновлении и обслуживании индексов.
- Оптимизированные индексные структуры: Использование индексов, оптимизированных для памяти, для ускорения поиска.
- Динамическое перераспределение индексов: Оптимизация и балансировка индексов в реальном времени для повышения производительности.
Слой запросов
- Операции поиска по вектору: Поиск ближайших соседей с заданной точностью (Approximate Nearest Neighbor, ANN); поддержка точного поиска k-NN для критичных к точности приложений.
- Комбинированные фильтры: Сочетание поиска векторов и фильтров метаданных с использованием логических операций; поддержка сложных запросов с вложенными условиями.
- Оптимизация производительности: Использование маршрутизации запросов, кэширование часто запрашиваемых данных и оптимизация набора результатов с ранним завершением.
Сервисный слой
- Проектирование API: Поддержка RESTful API и gRPC для высокопроизводительной связи клиент-сервер, а также обеспечение обратной совместимости с использованием версий API.
- Безопасность: Механизмы аутентификации и авторизации, шифрование данных на уровне хранения и передачи, а также ведение аудита всех операций.
- Масштабируемость: Стратегии балансировки нагрузки, горизонтальное масштабирование с автоматическим шардированием и управление кластером с мониторингом состояния узлов.
Операционные аспекты
Мониторинг
- Отслеживание производительности: Мониторинг метрик производительности, использования ресурсов, времени задержки запросов и выявление ошибок.
- Диагностика системы: Проведение регулярных проверок состояния системы и диагностика сбоев.
Техническое обслуживание
- Резервное копирование и восстановление: Процедуры резервного копирования и восстановления данных с поддержкой восстановления на определённый момент времени.
- Обновление версий и миграция данных: Обновление версий с возможностью отката, а также стратегии миграции данных между кластерами.
Высокая доступность
- Механизмы отказоустойчивости: Автоматическое восстановление при сбоях, репликация данных между географическими регионами и регулярное тестирование планов восстановления.
Лучшие практики
Подготовка векторов
- Предобработка данных: Очистка и нормализация данных перед векторизацией, обработка пропущенных значений и выбросов, а также стандартизация обработки изображений и текста для консистентных результатов.
- Генерация векторов: Выбор подходящих моделей эмбеддингов, поддержка одинаковых размерностей для схожих типов данных и использование доменно-специфических моделей для повышения качества представлений.
Управление индексами
- Выбор индекса: Выбор типа индекса в зависимости от размера набора данных и шаблонов запросов, планирование будущего роста данных.
- Конфигурация и обслуживание: Настройка параметров индекса, проведение регулярного обслуживания и минимизация фрагментации индекса.
Оптимизация запросов
- Параметры поиска: Настройка порогов сходства, оптимизация размера пакетов для массовых операций и балансировка точности и полноты результатов.
- Стратегии фильтрации: Разработка эффективных фильтров для метаданных и кэширование результатов запросов для повышения производительности.
Операционная эффективность
- Мониторинг и резервное копирование: Настройка комплексного логирования, создание стратегии резервного копирования и проведение тестов восстановления.
- Масштабирование: Планирование горизонтального и вертикального масштабирования, а также документирование процедур и стратегий масштабирования.
Безопасность
- Контроль доступа: Реализация механизмов аутентификации, настройка ролевого контроля доступа и регулярные проверки безопасности.
- Защита данных: Шифрование данных на уровне хранения и передачи, управление ключами и соответствие нормативным требованиям по защите данных.
Тестирование и валидация
- Качество и производительность: Проведение нагрузочного тестирования, проверка результатов поиска и мониторинг производительности системы.
- Стратегия развёртывания: Реализация развёртывания в стиле blue-green, поддержка отката версий и проведение регулярных тестов на восстановление после сбоев.
Бэнчмарк векторных бд
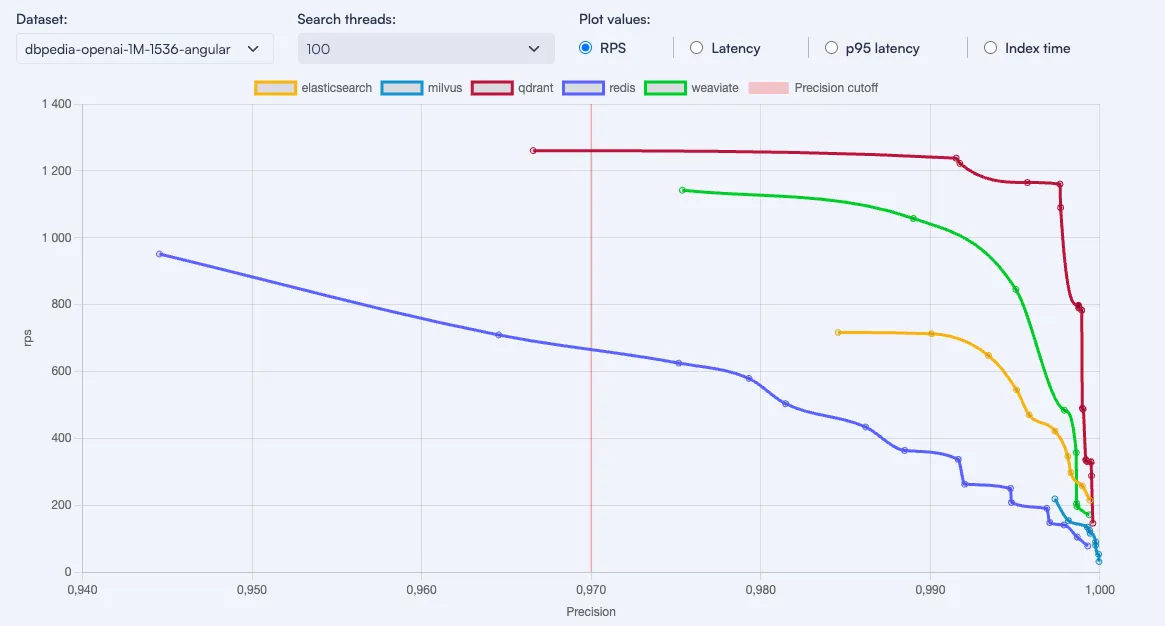
Проведенное тестирование несколько векторных баз данных, используя различные конфигурации на разных наборах данных, чтобы проверить, как могут изменяться результаты. Эти наборы данных имеют различную размерность векторов и также различаются по используемой функции расстояния. Так же при тестированиии пытались уловить разницу, которую можно ожидать при использовании различных параметров конфигурации, как для самого движка, так и для операции поиска отдельно.
| Engine | Setup | Dataset | Upload Time (m) | Upload + Index Time (m) | Latency (ms) | P95 (ms) | P99 (ms) | RPS | Precision |
|---|---|---|---|---|---|---|---|---|---|
| qdrant | qdrant-sq-rps-m-64-ef-512 | dbpedia-openai-1M-1536-angular | 3.51 | 24.43 | 3.54 | 4.95 | 8.62 | 1238.0016 | 0.99 |
| weaviate | latest-weaviate-m32 | dbpedia-openai-1M-1536-angular | 13.94 | 13.94 | 4.99 | 7.16 | 11.33 | 1142.13 | 0.97 |
| elasticsearch | elasticsearch-m-32-ef-128 | dbpedia-openai-1M-1536-angular | 19.18 | 83.72 | 22.10 | 72.53 | 135.68 | 716.80 | 0.98 |
| redis | redis-m-32-ef-256 | dbpedia-openai-1M-1536-angular | 92.49 | 92.49 | 140.65 | 160.85 | 167.35 | 625.27 | 0.97 |
| milvus | milvus-m-16-ef-128 | dbpedia-openai-1M-1536-angular | 0.27 | 1.16 | 393.31 | 441.32 | 576.65 | 219.11 | 0.99 |
И в жизни, и в программном обеспечении есть компромиссы, но некоторые явно работают лучше:
-
Qdrant достигает наивысшего количества запросов в секунду (RPS) и самой низкой задержки почти во всех сценариях, независимо от порога точности и выбранной метрики. Он также показал четырехкратное увеличение RPS на одном из наборов данных.
-
Elasticsearch стал значительно быстрее во многих случаях, но очень медленный по времени индексации. Он может быть в 10 раз медленнее при сохранении более 10 миллионов векторов размерности 96! (32 минуты против 5,5 часов).
-
Milvus является самым быстрым с точки зрения времени индексации и поддерживает хорошую точность. Однако он уступает другим по RPS и задержке, если использовать эмбеддинги с большей размерностью или большее количество векторов.
-
Redis способен достигать хорошего RPS, но в основном при низкой точности. Он также показал низкую задержку с одним потоком, однако задержка быстро возрастает при увеличении количества параллельных запросов. Часть прироста скорости объясняется использованием собственного протокола.