Векторные базы данных: Практическое руководство по Chroma DB
MLPops / January 02, 2025
10 мин.
Chroma DB - это современная векторная база данных, которая отлично подходит для хранения и поиска эмбеддингов. В этой статье мы рассмотрим основные шаги по настройке и использованию Chroma DB.
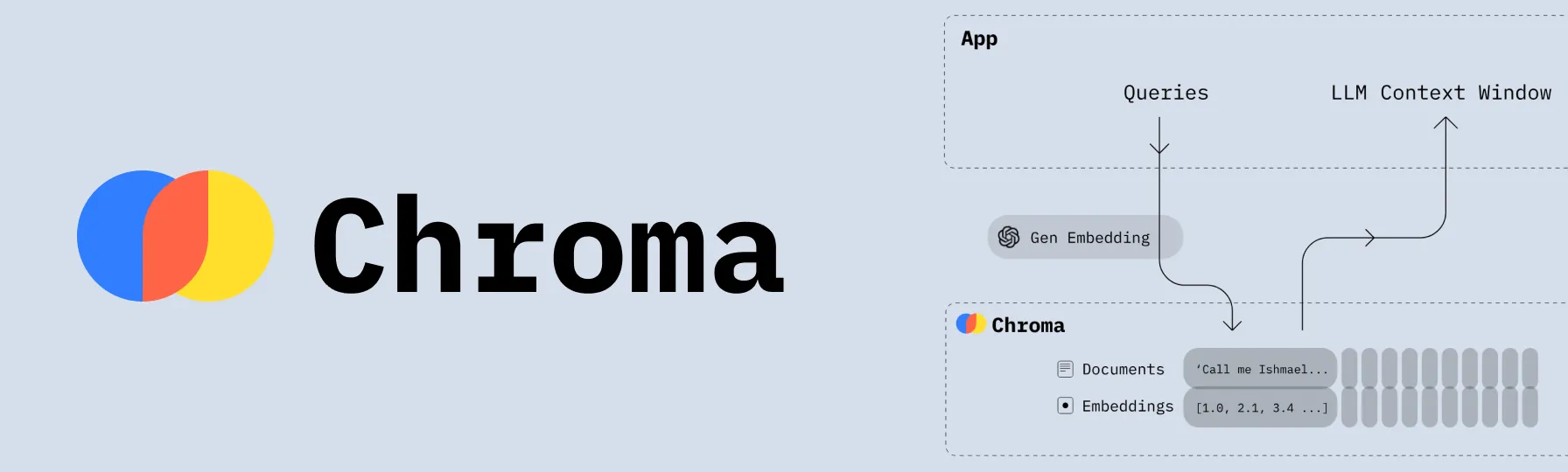
Основной функционал Chroma DB
1. Эффективное хранение эмбеддингов 💾
Chroma DB оптимизирована для хранения большого количества векторных представлений данных. Она использует передовые методы индексации и сжатия, что позволяет компактно хранить векторы без ущерба для скорости доступа.
2. Быстрый поиск по схожести ⚡
База данных обеспечивает высокоскоростной поиск похожих векторов, что критически важно для AI-приложений, таких как:
- Семантический поиск 🔍
- Рекомендательные системы 🎯
3. Масштабируемость 📈
Chroma DB способна эффективно работать с растущими объемами данных, используя многоядерные процессоры и большие объемы оперативной памяти на одной машине.
4. Управление метаданными 🗂️
Chroma DB поддерживает сложное управление метаданными, что позволяет выполнять комплексные запросы и поиск по схожести в больших наборах данных.
Варианты поиска 🔎
В Chroma DB доступны различные варианты поиска похожих векторов, основанные на разных метриках и пространствах. Вот основные опции:
Метрики расстояния 📐
-
L2 (Евклидово расстояние): Это метрика по умолчанию в Chroma DB. Она вычисляет прямое расстояние между двумя векторами в многомерном пространстве.
-
Косинусное расстояние: Измеряет угол между векторами, игнорируя их магнитуду. Это полезно, когда важна только направленность векторов.
-
Внутреннее произведение: Оценивает сходство векторов на основе их скалярного произведения.
-
Манхэттенское расстояние: Вычисляет сумму абсолютных разностей координат векторов.
-
Расстояние Хэмминга: Подсчитывает количество позиций, в которых соответствующие элементы двух векторов различаются.
Пространства поиска 🌌
Chroma DB позволяет настроить пространство поиска при создании коллекции:
collection = client.create_collection(
name="collection-1",
metadata={"hnsw:space": "cosine"}
)Доступные опции включают:
- “l2”: Евклидово пространство (по умолчанию)
- “cosine”: Косинусное пространство
- ”ip”: Пространство внутреннего произведения
Алгоритмы поиска 🚀
Chroma DB использует алгоритм Hierarchical Navigable Small World (HNSW) для приближенного поиска ближайших соседей (ANN). Этот алгоритм создает графовую структуру, соединяющую похожие векторы, что позволяет быстро выполнять запросы даже в больших наборах данных.
Настройка поиска
При выполнении запроса можно указать желаемую метрику расстояния:
results = collection.query(
query_embeddings=[query_vector],
n_results=5,
distance_metric="cosine"
)Выбор подходящей метрики и пространства поиска зависит от конкретной задачи и характеристик данных. Например, косинусное расстояние часто используется для текстовых данных, так как оно менее чувствительно к длине документов.
Hierarchical Navigable Small World
Hierarchical Navigable Small World (HNSW) - это эффективный алгоритм для приближенного поиска ближайших соседей в высокоразмерных пространствах. Вот как он работает:
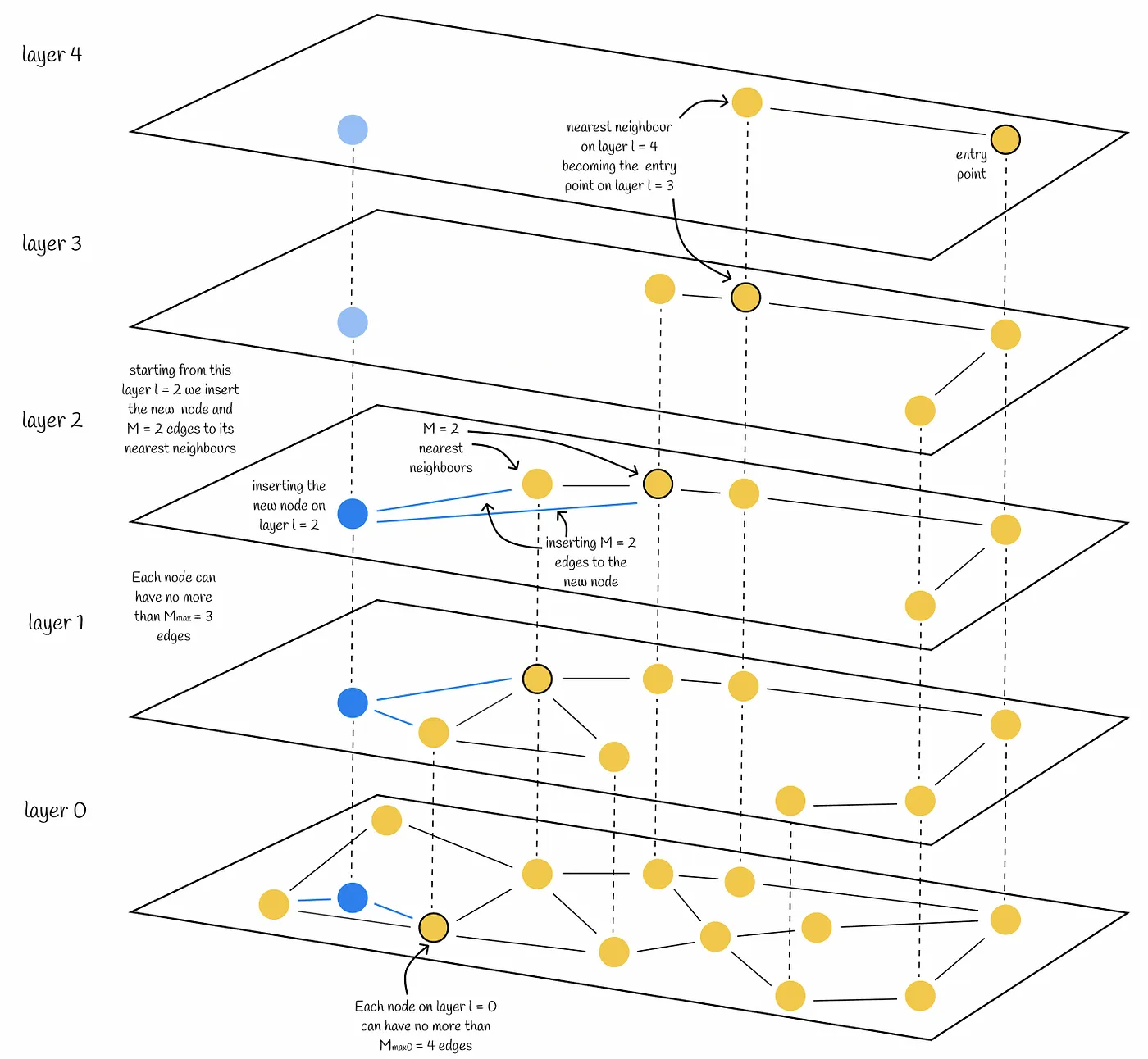
Структура графа
HNSW строит многоуровневый граф, где каждый уровень представляет собой “малый мир”:
- Нижний уровень (уровень 0) содержит все векторы в наборе данных.
- Верхние уровни содержат меньше векторов, выбранных случайным образом.
- Каждый вектор появляется на своем уровне вставки и всех уровнях ниже него.
- Векторы на верхних уровнях имеют больше соединений.
Процесс построения
- При добавлении нового вектора, алгоритм случайно выбирает его максимальный уровень.
- Вектор добавляется на этот уровень и все уровни ниже.
- На каждом уровне устанавливаются связи с ближайшими соседями.
Процесс поиска
- Поиск начинается с входной точки на верхнем уровне.
- На текущем уровне выполняется жадный поиск, переходя к ближайшему соседу запроса.
- Когда более близкие соседи не найдены, поиск спускается на уровень ниже.
- Шаги 2-3 повторяются до достижения уровня 0.
- На уровне 0 выполняется финальный поиск для нахождения k ближайших соседей.
Ключевые особенности
- Логарифмическая сложность поиска O(log N) на практике.
- Балансированная структура с дальними связями на верхних уровнях и короткими на нижних.
- Эффективное сочетание глобальной и локальной навигации.
- Возможность инкрементных обновлений без полной перестройки индекса.
HNSW обеспечивает высокую скорость и точность поиска, особенно в больших наборах данных, что делает его популярным выбором для векторных баз данных и систем рекомендаций.
ЗаЗапуск ChromaDB через Docker 🐳
Для начала давайте поднимем Chroma DB в Docker контейнере. Это простой и удобный способ быстро начать работу.
- Убедитесь, что у вас установлен Docker.
- Выполните следующую команду для запуска Chroma DB:
docker run -d --rm --name chromadb -p 8000:8000 \
-v ./chroma:/chroma/chroma \
-e IS_PERSISTENT=TRUE chromadb/chroma:0.5.13Эта команда:
- Запускает контейнер в фоновом режиме (
-d) - Удаляет контейнер после остановки (
--rm) - Называет контейнер “chromadb” (
--name chromadb) - Проксирует порт 8000 (
-p 8000:8000) - Монтирует локальную директорию для хранения данных (
-v ./chroma:/chroma/chroma) - Устанавливает переменную окружения для персистентности (
-e IS_PERSISTENT=TRUE) - Использует образ
chromadb/chromaверсии0.5.13
Подключение к Chroma DB
После запуска контейнера, мы можем подключиться к Chroma DB с помощью Python клиента.
- Установите клиентскую библиотеку:
pip install chromadb-client- Подключитесь к базе данных:
import chromadb
client = chromadb.HttpClient(host="localhost", port=8000)- Создайте коллекцию:
collection = client.create_collection(name="my_collection")Добавляем в коллекцию
Distilbert - это облегченная версия BERT, которая отлично подходит для создания эмбеддингов текста. Давайте рассмотрим пример его использования с Chroma DB.
- Установите необходимые библиотеки:
pip install transformers torch- Создайте функцию для генерации эмбеддингов:
from transformers import DistilBertTokenizer, DistilBertModel
import torch
tokenizer = DistilBertTokenizer.from_pretrained('distilbert-base-uncased')
model = DistilBertModel.from_pretrained('distilbert-base-uncased')
def get_embeddings(texts):
inputs = tokenizer(texts, return_tensors="pt", padding=True, truncation=True, max_length=512)
with torch.no_grad():
outputs = model(**inputs)
return outputs.last_hidden_state[:, 0, :].numpy()- Используйте эту функцию при добавлении документов в Chroma DB:
documents = ["This is a sample document", "Another example text"]
embeddings = get_embeddings(documents)
collection.add(
documents=documents,
embeddings=embeddings.tolist(),
ids=["doc1", "doc2"]
)Работа с моделью CLIP
CLIP (Contrastive Language-Image Pre-training) - это модель, которая может работать как с текстом, так и с изображениями. Давайте рассмотрим пример его использования для создания эмбеддингов изображений.
- Установите необходимые библиотеки:
pip install torch torchvision transformers Pillow- Создайте функцию для генерации эмбеддингов изображений:
from PIL import Image
import torch
from torchvision.transforms import Compose, Resize, CenterCrop, ToTensor, Normalize
from transformers import CLIPProcessor, CLIPModel
model = CLIPModel.from_pretrained("openai/clip-vit-base-patch32")
processor = CLIPProcessor.from_pretrained("openai/clip-vit-base-patch32")
def get_image_embeddings(image_paths):
images = [Image.open(path) for path in image_paths]
inputs = processor(images=images, return_tensors="pt", padding=True)
with torch.no_grad():
outputs = model.get_image_features(**inputs)
return outputs.numpy()- Используйте эту функцию для добавления изображений в Chroma DB:
image_paths = ["path/to/image1.jpg", "path/to/image2.jpg"]
embeddings = get_image_embeddings(image_paths)
collection.add(
documents=image_paths,
embeddings=embeddings.tolist(),
ids=["img1", "img2"]
)Пример поиска похожих статей
Рассмотрим пример использования Chroma DB для поиска похожих статей на основе их содержания. Мы будем использовать модель DistilBERT для создания векторных представлений текста.
import chromadb
from transformers import DistilBertTokenizer, DistilBertModel
import torch
# Инициализация клиента Chroma DB
client = chromadb.Client()
# Создание коллекции для статей
collection = client.create_collection("articles")
# Инициализация модели DistilBERT
tokenizer = DistilBertTokenizer.from_pretrained('distilbert-base-uncased')
model = DistilBertModel.from_pretrained('distilbert-base-uncased')
# Функция для получения эмбеддингов
def get_embeddings(texts):
inputs = tokenizer(texts, return_tensors="pt", padding=True, truncation=True, max_length=512)
with torch.no_grad():
outputs = model(**inputs)
return outputs.last_hidden_state[:, 0, :].numpy()
# Пример статей
articles = [
{
"id": "1",
"title": "The Future of AI",
"content": "Artificial intelligence is rapidly evolving, transforming various industries..."
},
{
"id": "2",
"title": "Climate Change Challenges",
"content": "Global warming continues to pose significant threats to our planet..."
},
{
"id": "3",
"title": "Advancements in Quantum Computing",
"content": "Quantum computers are making breakthroughs in solving complex problems..."
}
]
# Добавление статей в коллекцию
for article in articles:
embedding = get_embeddings([article['content']])[0]
collection.add(
documents=[article['content']],
embeddings=[embedding.tolist()],
metadatas=[{"title": article['title']}],
ids=[article['id']]
)
# Функция поиска похожих статей
def find_similar_articles(query_text, n_results=2):
query_embedding = get_embeddings([query_text])[0]
results = collection.query(
query_embeddings=[query_embedding.tolist()],
n_results=n_results
)
return results
# Пример использования
query = "The impact of technology on modern society"
similar_articles = find_similar_articles(query)
print("Похожие статьи:")
for i, (doc, metadata) in enumerate(zip(similar_articles['documents'][0], similar_articles['metadatas'][0])):
print(f"{i+1}. {metadata['title']}")
print(f" Excerpt: {doc[:100]}...")
print()
В этом примере мы:
- Инициализировали клиент Chroma DB и создали коллекцию для статей.
- Настроили модель DistilBERT для создания векторных представлений текста.
- Добавили несколько статей в коллекцию, сохраняя их содержание, эмбеддинги и метаданные.
- Создали функцию для поиска похожих статей на основе текстового запроса.
- Продемонстрировали использование функции поиска.
Этот пример показывает, как Chroma DB может быть использована для создания системы рекомендаций статей или поисковой системы, основанной на семантическом сходстве текстов. Важно отметить, что Chroma DB эффективно хранит векторные представления и позволяет быстро находить наиболее похожие документы, что делает ее идеальным выбором для подобных задач.
Пример использования чанкинга
Чанкинг (или разбиение на чанки) — это процесс деления больших текстов на меньшие фрагменты, что позволяет более эффективно обрабатывать и индексировать данные. В контексте работы с Chroma DB это особенно полезно для поиска по большим статьям, так как позволяет создать векторные представления для каждого чанка и улучшить качество поиска.
Пример: Чанкинг для больших статей
Рассмотрим пример, в котором мы разбиваем большие статьи на чанки, создаем векторные представления для каждого чанка и добавляем их в Chroma DB для последующего поиска.
Шаг 1: Импорт библиотек и инициализация Chroma DB
import chromadb
from transformers import DistilBertTokenizer, DistilBertModel
import torch
# Инициализация клиента Chroma DB
client = chromadb.Client()
# Создание коллекции для чанков статей
chunks_collection = client.create_collection("article_chunks")
# Инициализация модели DistilBERT
tokenizer = DistilBertTokenizer.from_pretrained('distilbert-base-uncased')
model = DistilBertModel.from_pretrained('distilbert-base-uncased')Шаг 2: Функция для чанкинга
Создадим функцию, которая будет разбивать текст статьи на чанки фиксированной длины.
def chunk_text(text, chunk_size=512):
# Разделение текста на предложения
sentences = text.split('. ')
chunks = []
current_chunk = ""
for sentence in sentences:
# Проверка на превышение размера чанка
if len(current_chunk) + len(sentence) + 1 <= chunk_size:
current_chunk += sentence + '. '
else:
chunks.append(current_chunk.strip())
current_chunk = sentence + '. '
# Добавление последнего чанка
if current_chunk:
chunks.append(current_chunk.strip())
return chunksШаг 3: Добавление чанков в Chroma DB
Теперь добавим функцию, которая будет обрабатывать статьи, разбивать их на чанки и добавлять в Chroma DB.
def add_article_to_db(article_id, article_title, article_content):
# Чанкинг статьи
chunks = chunk_text(article_content)
for i, chunk in enumerate(chunks):
# Получение эмбеддингов для каждого чанка
inputs = tokenizer(chunk, return_tensors="pt", padding=True, truncation=True)
with torch.no_grad():
outputs = model(**inputs)
embedding = outputs.last_hidden_state[:, 0, :].numpy()[0]
# Добавление чанка в коллекцию
chunks_collection.add(
documents=[chunk],
embeddings=[embedding.tolist()],
metadatas=[{"title": article_title}],
ids=[f"{article_id}_chunk_{i}"]
)Шаг 4: Пример использования
Теперь мы можем добавить статьи в базу данных. Например:
# Пример статьи
article_id = "1"
article_title = "The Future of AI"
article_content = (
"Artificial intelligence is rapidly evolving and transforming various industries. "
"From healthcare to finance, AI is making significant impacts. "
"In healthcare, AI algorithms can analyze medical data to assist in diagnostics. "
"In finance, AI is used for fraud detection and algorithmic trading. "
"The future of AI holds even more promise as technology continues to advance."
)
# Добавление статьи в базу данных
add_article_to_db(article_id, article_title, article_content)Шаг 5: Поиск по чанкам
Теперь мы можем реализовать функцию поиска по чанкам на основе текстового запроса.
def search_chunks(query_text, n_results=3):
# Получение эмбеддингов для запроса
query_inputs = tokenizer(query_text, return_tensors="pt", padding=True)
with torch.no_grad():
query_outputs = model(**query_inputs)
query_embedding = query_outputs.last_hidden_state[:, 0, :].numpy()[0]
# Поиск похожих чанков
results = chunks_collection.query(
query_embeddings=[query_embedding.tolist()],
n_results=n_results
)
return results
# Пример поиска по запросу
search_query = "impact of artificial intelligence"
search_results = search_chunks(search_query)
print("Результаты поиска:")
for i in range(len(search_results['documents'][0])):
print(f"{i + 1}. {search_results['metadatas'][0][i]['title']}: {search_results['documents'][0][i]}")В этом примере мы рассмотрели процесс чанкинга больших статей и их добавления в Chroma DB для эффективного поиска. Используя модель DistilBERT для создания эмбеддингов и разбивая текст на управляемые части (чанки), мы можем значительно улучшить качество поиска по содержимому статей. Это решение также позволяет легко масштабировать систему для работы с большим объемом текстовых данных.
Заключение 🏁
ChromaDB — это мощный инструмент для работы с векторными данными. Благодаря поддержке различных метрик расстояния, алгоритмов поиска и интеграции с моделями NLP/CV (например, DistilBERT или CLIP), она идеально подходит для задач семантического поиска и рекомендаций.